
How Good is 85%? A Survey Tool to Connect Classifier Evaluation to Acceptability of Accuracy
ACM Human Factors in Computing Systems (CHI) 2015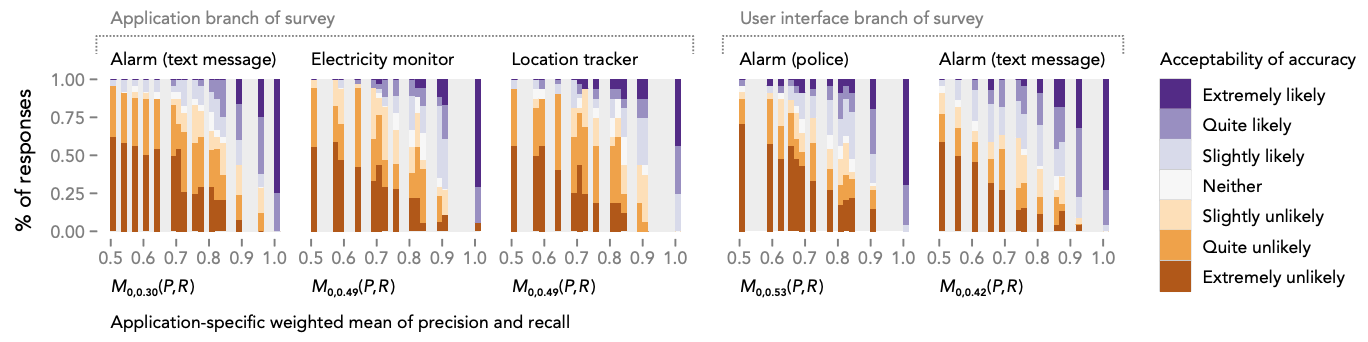
Acceptability of accuracy from the survey results plotted against each application’s weighted geometric mean of precision and recall from our model. Optimizing this mean has the effect of also optimizing an application’s acceptability of accuracy.
Abstract
Many HCI and ubiquitous computing systems are characterized by two important properties: their output is uncertain—it has an associated accuracy that researchers attempt to optimize—and this uncertainty is user-facing—it directly affects the quality of the user experience. Novel classifiers are typically evaluated using measures like the F1 score— but given an F-score of (e.g.) 0.85, how do we know whether this performance is good enough? Is this level of uncertainty actually tolerable to users of the intended application—and do people weight precision and recall equally? We set out to develop a survey instrument that can systematically answer such questions. We introduce a new measure, acceptability of accuracy, and show how to predict it based on measures of classifier accuracy. Out tool allows us to systematically select an objective function to optimize during classifier evaluation, but can also offer new insights into how to design feedback for user-facing classification systems (e.g., by combining a seemingly-low-performing classifier with appropriate feedback to make a highly usable system). It also reveals potential issues with the ubiquitous F1-measure as applied to user-facing systems.
Citation
BibTeX
@inproceedings{accuracy-acceptability-2015,
title = {How Good is 85\%? A Survey Tool to Connect Classifier Evaluation to Acceptability of Accuracy},
author = {Kay, Matthew and Patel, Shwetak N. and Kientz, Julie A.},
year = 2015,
booktitle = {Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems},
publisher = {ACM},
series = {CHI '15},
pages = {347–356},
doi = {10.1145/2702123.2702603}
}